


Arundo Analytics Launches Energy Optimization Application for Chlorine Electrolysis
Arundo Analytics is excited to launch an innovative solution reducing electricity costs based on forecasted electricity prices
Are you considering starting an industrial data science initiative but don’t know where to start? Here are 4 important things you should know.
Have you considered starting an industrial data science initiative but don’t know where to start? Keep on reading and I’ll tell you 4 important things you should know.
Machine learning can create value for an industrial company in 3 ways:
Let’s step through each of these in turn.
First, improving operational performance requires that we reduce downtime, detect equipment or process faults, and predict potential failures that would impact operations or production.
Second, in order to optimize systems and processes, we’re typically talking about supply chain improvements as well as production or process optimization.
Last but not least, perhaps the most promising value proposition for data science in asset-heavy industries is the possibility of using these capabilities to enable new business models. A good example of a new business model for a pump manufacturer enabled by industrial data science would be "pumping as a service" where the pump manufacturer charges a subscription that includes guaranteed pump uptime and pump maintenance versus selling the pump itself. Recurring revenue is valued much more highly by financial markets than a one-time sale due to the fact that the recurring revenue streams continue for many years, effectively into perpetuity.
Whether you’re embarking on a comprehensive digital transformation or a specific machine learning enabled use case, it’s important to evaluate and quantify the value of the new capability to estimate its potential impact. As a result, you’ll also find its importance to your enterprise. It’s also critical to determine which use cases are actually feasible given the data at hand and supporting systems of record. Our perspective is that you can build digital competency and achieve significant value rapidly when you focus on iterative and incremental deployments that leverage existing data and systems.
Machine learning is well positioned to answer critical operational questions such as
To ensure the highest probability of success, we advise our customers to focus on value and feasibility. We find it better to start with the "quick wins" to build competency, learn, and then iterate. Assuming you deploy several "quick win" use cases in a relatively short time period, say over several months or a year, you’ll often find that the value adds up.
From our experience, understanding the feasibility is the most important thing to master when prioritizing which use cases to address. This requires a cross-functional team of subject matter experts (often reliability, process, or production engineers), IT solution architects, data engineers, and data scientists. This is a non-trivial effort that requires a meaningful time investment. However, this investment pays off in spades if you execute it well. It can prevent you from going down the “digital rabbit hole” chasing a use case that truly isn’t currently feasible. In addition, the feasibility exercise provides you with a solid fact base you can use to architect the ideal solution for your organization.
The first thing to understand is what kind of historical data you have available. To build a predictive failure model, you need historical sensor data as well as well-labeled "event" data outlining when and what type of failure occurred. Typically, a supervised machine learning model is developed leveraging this labeled historical event data.
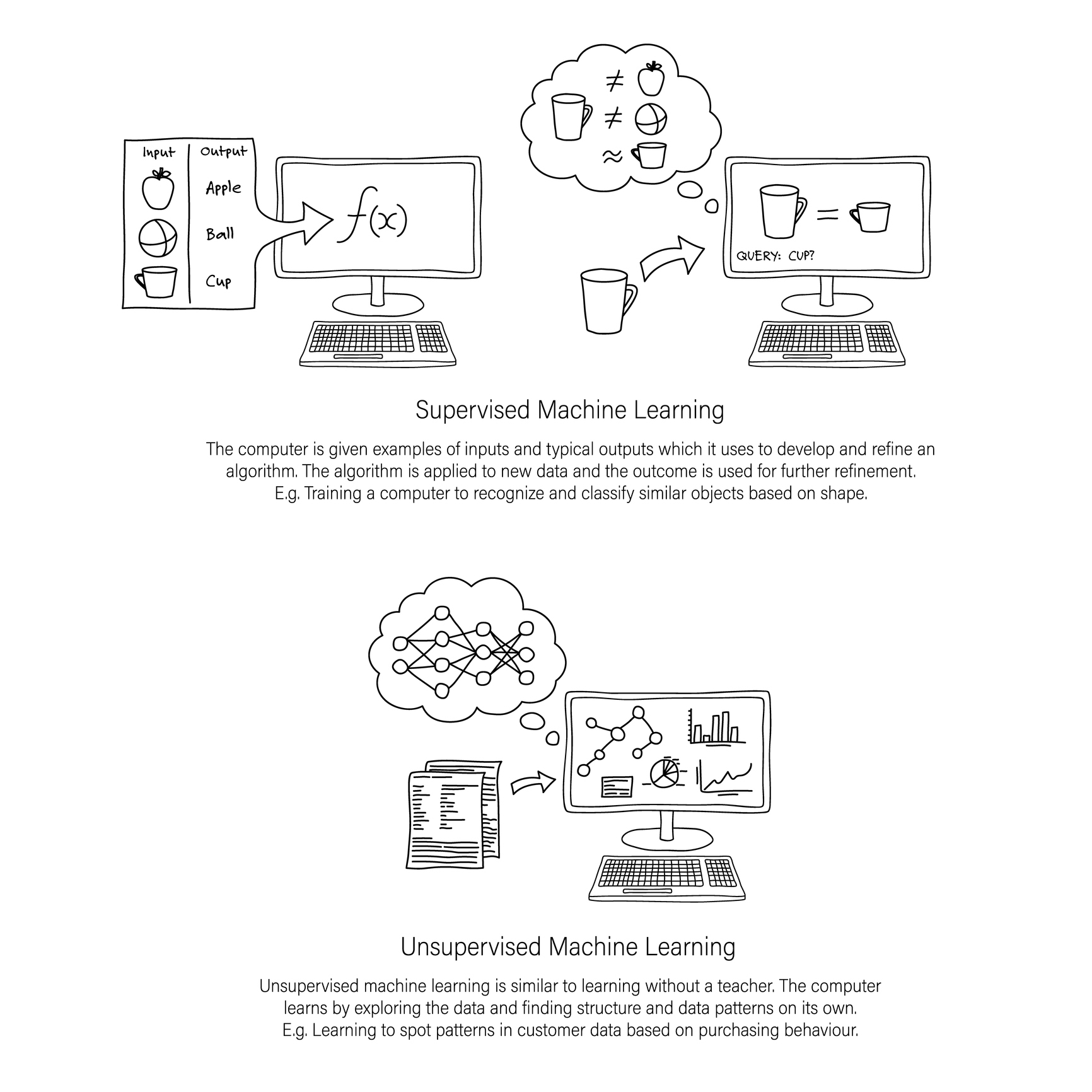
The reality in practice however, is that many industrial companies don’t have well labeled historical event data, due to a variety of reasons. In these instances an unsupervised machine learning approach can be applied. The image below outlines the difference between supervised and unsupervised machine learning in more detail.
If this well-labeled historical data exists, you can take a supervised machine learning approach. However, this supervised approach requires a large volume of well-labeled event data. From our experience, most companies do not possess the required volume of well-labeled event data.
In these cases, you must pursue an unsupervised machine learning approach. Typically, an unsupervised approach involves some kind of clustering analysis to determine anomalous operating conditions. It's best practice to partner a data scientist with the asset subject matter expert to determine and define what anomalous operations mean for the particular asset in question. To do this, the data scientist must identify sensor data that defines these anomalous operating conditions. The reliability engineer can review potential anomalous event data that's identified and confirm/deny that an anomaly event happened. In this way, we can gather labeled data over time that will help us improve the ability of the model to predict potential failure modes. Through this approach, industrial companies can overcome the lack of historical data to provide value to the business through preventative maintenance enabled by data science.
Data science can solve many challenging business problems experienced in industrial operations, as well as enable the delivery of new innovative and high-value business models. It’s important to get started on the digital journey with projects that are feasible today using the systems of record and data sets that can be accessed easily. In our experience, there is almost always untapped value in these data-sets and focusing on initial use cases that are feasible to deliver within a 2-3 month period helps the organization capture a few quick wins to build value, competency, and momentum for more ambitious digital initiatives. We've seen that the risk of failure can be mitigated by starting small, iterating fast, and incrementally adding more sophisticated analytics. An 80% solution deployed at scale across all of your assets will always be worth more than a 100% solution deployed at a single asset.
Learn more
Rapid IoT Projects in Industry - Where Should You Focus?
How to Start Thinking About Architecture for Data-Driven Solutions
Why is Industrial IoT Implementation so Hard?
Implementing IIoT - 6 Critical Factors you Need to Consider

A stanford-startx company
an MIT stex25 company
© 2022 ARUNDO - All rights reserved

